
This post is part of a series covering the architecture of Elasticsearch based on my experience while working with it. In this post, we’ll be discussing how the cluster works, try to find answers for following questions:
- How a node in cluster talks to others?
- What happens when a node joins or leaves the cluster?
- What happens when a node stops or has encountered a problem?
A Cluster of Nodes
When we start an instance of Elasticsearch, we are starting a node and we have a cluster with single node. We start another instance of Elasticsearch has same cluster.name with the first instance and we have a cluster with two nodes. We can start more instances of Elasticsearch to form a cluster with number of nodes we want.
Every node in the cluster knows about the other nodes within the cluster, they talk to others directly using the native Elasticsearch language over TCP. This is known as a full connected mesh topology:
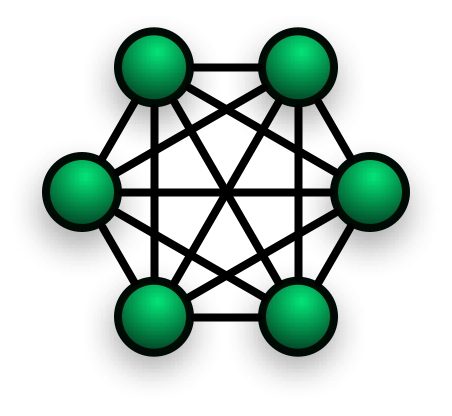
Figure 1. Full connected mesh topology (source https://upload.wikimedia.org/wikipedia/commons/3/3c/NetworkTopology-FullyConnected.png)
Besides that, the nodes are able to talk to external world using JSON “language” over HTTP.
So, we can say:
Elasticsearch is peer-to-peer based system, nodes communicate with others directly.
Each node in the cluster plays one or more roles; it can be a master node, data node, client node, or tribe node. Ech role has it own purpose.
The master node is responsible for creating, deleting indices, adding the nodes or remove the nodes from the cluster. Each time a cluster state is changed, the master node broadcasts the changes to other nodes in the cluster. There is only one master node in the cluster at a time.
The data node is responsible for holding the data in the shards and performing data related operations such as create, read, update, delete, search, and aggregations. We can have many data nodes in the cluster. If one of the data nodes stops, the cluster still operates and re-organizes the data on other nodes.
The client node is responsible for routing the cluster-related requests to the master node and the data-related requests to the data nodes, it acts as a “smart router”. The client node does not hold any data, it also cannot become the master node.
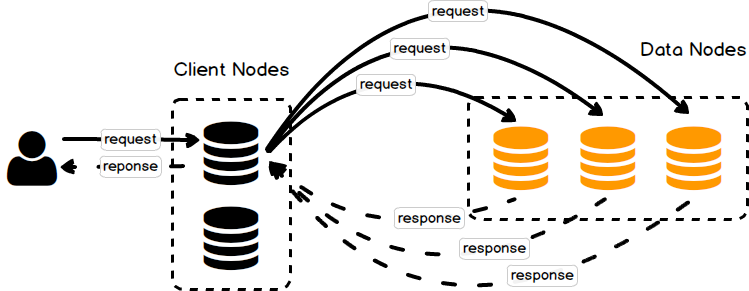 Figure 2. The client node routes the data-related request to every data nodes in the cluster.
Figure 2. The client node routes the data-related request to every data nodes in the cluster.
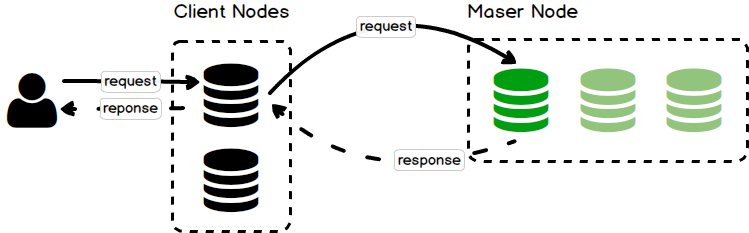 Figure 3. The client node routes the cluster-related request to the master node in the cluster.
Figure 3. The client node routes the cluster-related request to the master node in the cluster.
The tribe node is special type of client node that is able to talk to multiple clusters to perform search and other operations.
The ingest node is responsible for pre-processing documents before the actual indexing takes into account.
Now we know role of each node, next we look at what happens behind the sence when a node joins or leaves the cluster.
Add a Node to the Cluster
When we start a node, the node is starting to ping all the nodes in the cluster for finding the master node. Once the master is found, it will ask the master to join by sending a join request; the master accepts it as a new node of the cluster and then notify all the nodes in the cluster about presense of the new node, and finally the new node connects to all other nodes.
If the joined node is a data node, the master will reallocate the data evenly across the nodes.
Remove a Node from the Cluster
If we stop a node or a node in the cluster is unresponsive in specific amout of time, the master node will remove it from the cluster and reallocate the data if the removed node is a data node.
You might be curious about how the master node knows if other nodes in the cluster are still alive. The master has a fault detection machanism, it pings all the other nodes in the cluster and verify that they are alive or not.
And about the master, what happens if it stops or has encountered a problem? Same the master node, each node in the cluster also have a fault detection machanism, it pings to master to verify if its still alive. If the master is not alive, other master-eligible nodes will be elected new master to replace the down one within seconds.
In the next post in this series, we will look at how Elasticsearc index data in a distributed maner.