When a document is stored in Elasticsearch, it is indexed and fully searchable within 1 second. Elasticsearch uses an inverted index data structure that supports full-text searches efficiently and very fast.
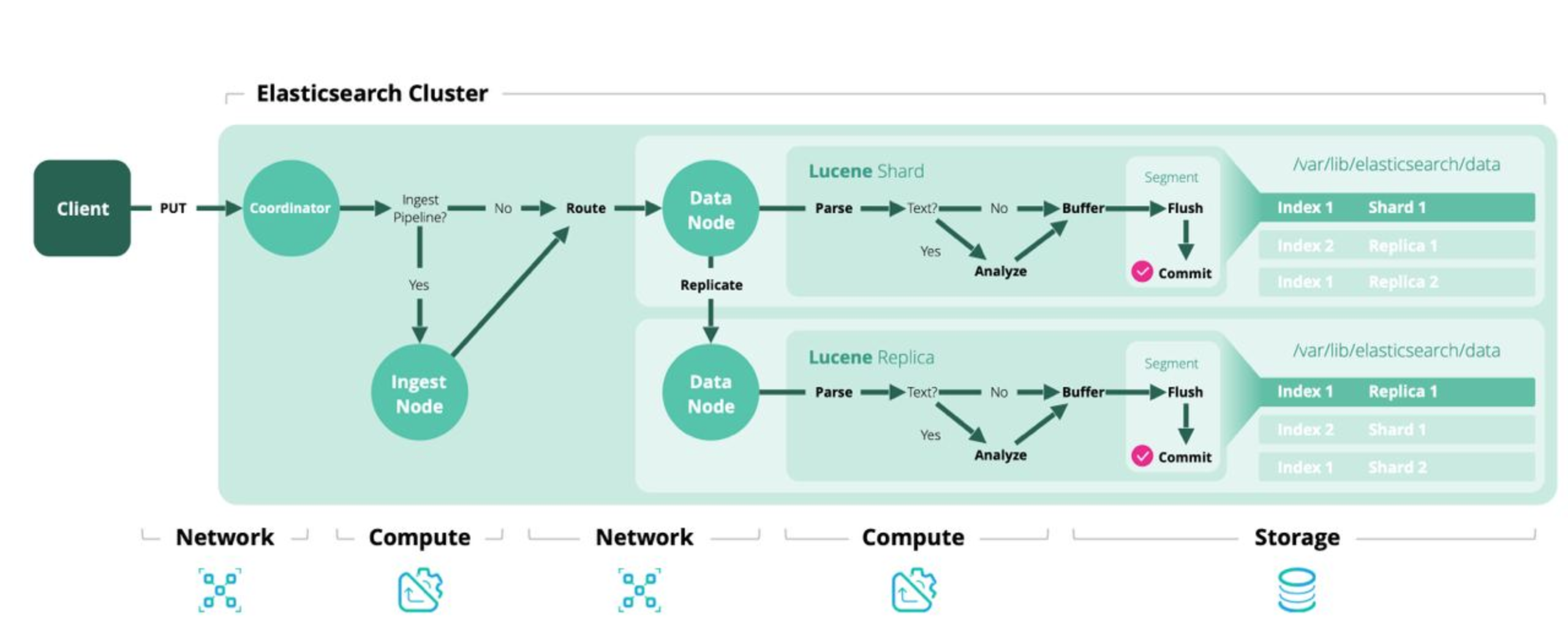
The above diagram shows the data flow when a document is indexed into a Elasticsearch cluster. It includes following basic steps:
Step 1: The client makes a request to put a document into the cluster, a coordinator node in the cluster takes the request to process.
Step 2: The coordinator node uses the pipeline parameter in the indexing request to check if the document needs to
be enriched or transformed before routing to a data node for further processing.
If answer is No, the document is routed to a data node in the cluster. If the answer is Yes, the document is routed to an ingest node in the
cluster to enrich the document. When the enriching process is done, the ingest node continues routing the enriched document to the data node.
Decision of which data node in the cluster will take the document to process further is based on index’s shard information and the hashing modulo formular:
shard = hash(routing) % number_of_shards
Step 3: The data node parses the document to a JSON object then checking if there is any text values in the object.
If the text values are found, a text analysis process will be involved. It analyzes, breaks the text into more
useful structural components. It also applies some processing to make the document more relevant to fulltext search.
Finally, the document is added to a memory buffer and appended to the transaction log.
When the buffer fills up, the documents are written to a segment and then the buffer is clear. In the meantime, the transaction log still keeps the documents until it gets big enough, a full commit is performed. The documents is flushed to disk permanently, the old transaction log is deleted and the new one is created.
If the replication is enabled, the replication data process are triggered. This data node sends a replication request to a data node which contains replicas shards of the index. The whole indexing process here will be done on that node to create a copy of those documents.